最近利用业余时间写了一个简单的分布式对象存储yfs,分布式一致性构建在atomix之上。atomix实现了raft,并且提供了更高层次的抽象,例如Map、Set、DistributedLock等。为了详细的阐述遇到问题的来龙去脉,有必要简单阐述下yfs的架构,架构图如下:
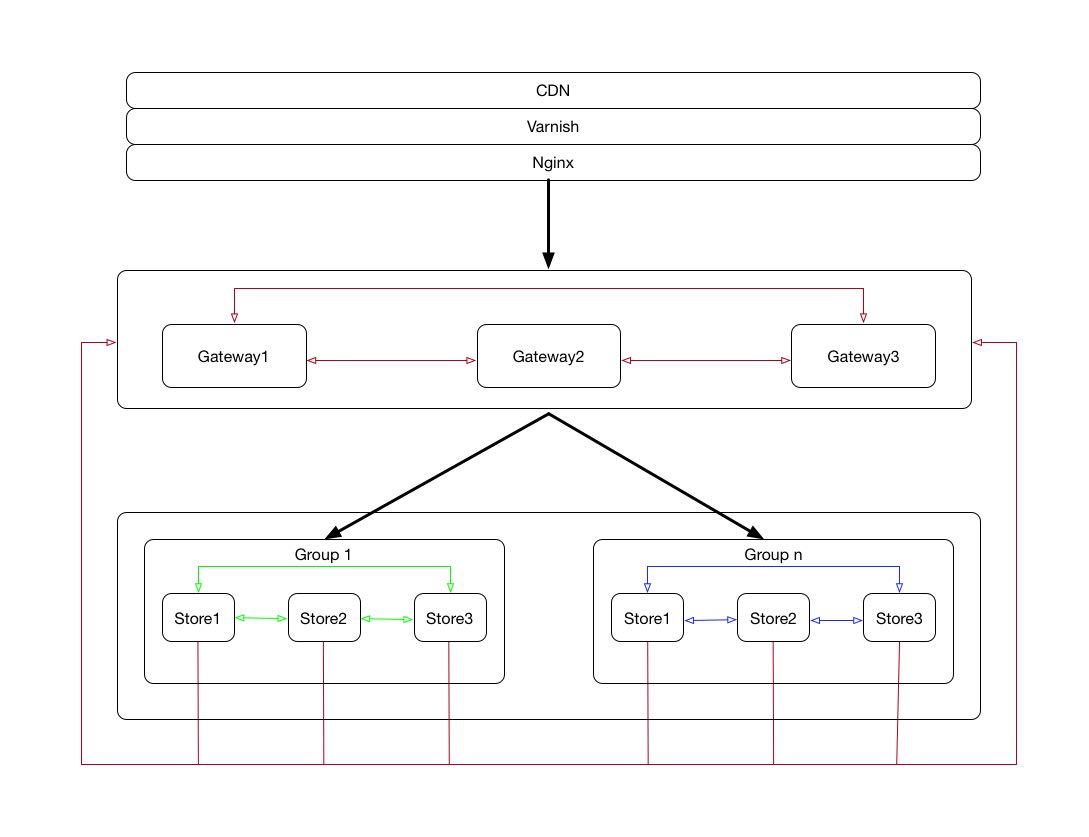
从上图可知yfs由Gateway和分组的Store两部分组成,Gateway主要负责路由、鉴权、流控、安全等非存储功能,Store主要负责存储。每个Group至少由三个Store节点组成,这三个Store所存储的数据一模一样,也就是说每个文件至少有三个备份。Gateway也至少有三个节点,Store节点会自动上报metadata给Gateway,Gateway根据Store节点上报的信息来调整自己的路由策略。Gateway是在我的例外一个开源项目waf的基础上改造的而来的,每个Store节点都运行着一个Springboot服务,用来提供上传和下载服务。
问题一
当上传的文件大于Store允许上传的文件size时,发现前端一直在等待响应结果,HTTP请求传递过程是Browser->Gateway->Store。
分析
- 首先尝试在Store上debug上传接口,发现请求压根就没有进入到controller,一搜发现https://stackoverflow.com/questions/21089106/converting-multipartfile-to-java-io-file-without-copying-to-local-machine里面已经说的很清楚,原来只有等文件上传完成之后,才会进入到controller中。
- 那为什么没有上传完成呢,wireshark一抓包发现,当数据上传部分之后,Tomcat TCP端口突然发送了一个RST,为什么会出现这种情况呢?一查原来当Tomcat发现上传的文件大于允许上传的文件时,Tomcat就直接RST TCP链接。其实原因很简单,既然上传的文件不符合规范,后面的数据包即使发送过来也会被扔掉,那与其这样,不如不要上传了,还节省上传宝贵的网络带宽。思路是没有错,但是这样HTTP层面就拿不到任何数据,浏览器最多报一个网络异常,例如Chrome会出现net::ERR_CONNECTION_RESET。假如我们允许上传的最大文件是10M,如果上传的文件大于10M小于20M,我们希望返回一个http response告诉前端上传的文件不符合规范,20M以上我们就认为是异常流量或者攻击直接RST TCP。这样的方案既方便测试,又对使用者友好,那该如何实施呢?
- Tomcat的配置参数MaxSwallowSize从意思上来说已经非常清晰,由于Store节点运行的是Springboot服务,所以需要重新配置TomcatEmbeddedServletContainerFactory。设置之后经测试发现20M以下的,前端会迅速收到响应结果,但是20M以上的还是存在问题,因为20M以上的Tomcat还是会RST TCP。
- 通过netstat发现Gateway->Store之间的链路RST之后,Browser->Gateway之间的链路并没有断开,看来问题的关键就在这里了。发现问题的关键点之后,改起来就简单,我在Gateway上给Gateway->Store之间的channel加了一个CloseFuture Listener从而去关闭Browser->Gateway之间的channel,经测试发现问题解决。
问题二
正当我准备逛下论坛庆祝一下的时候,运维部署到了测试环境,结果任何请求Nginx都报upstream prematurely closed connection while reading upstream,顿时我就懵逼了。
分析
测试环境HTTP请求传递过程是Browser->Nginx->Gateway->Store,跟我开发环境不太一样,多了一层Nginx,通过错误信息可以知道Nginx的upstream也就是Gateway出现了问题。
- connection close,那么必然会出现TCP关闭,在Nginx服务器上经过抓包一看,发现Gateway主动关闭了Nginx->Gateway之间的TCP通道。到Gateway服务器上抓包,发现Gateway先关闭了Gateway->Store之间的通道,然后由于CloseFuture Listener接着关闭Nginx->Gateway之间的通道。Gateway每次都主动发起关闭,为什么会这样呢?我本地从来没有出现过这样的现象,Gateway和Store之间应该是长连接才对啊。
- 仔细分析整个链路,先是Browser->Nginx,发现走的HTTP1.1,没有任何问题,但是Nginx->Gateway却走的HTTP1.0,看来问题的关键就出在这个地方了。原来当Store返回响应结果之后,由于HTTP1.0是短链接,所以Gateway主动发起关闭。由于我前面给Gateway->Store的channel加了关闭的监听,所以Nginx->Gateway之间的channel也会立即关闭,所以导致Nginx会报上面的错误。
接着检查了Nginx的配置,果然发现Nginx到Gateway之前HTTP1.1的配置不正确,加入如下配置之后问题解决。
1
2proxy_http_version 1.1;
proxy_set_header Connection "";所以
CloseFuture Listener方案只能工作在HTTP1.1之上,也就是说Gateway->Store之间channel的关闭,只可能是由于idle超时或者异常关闭,否者就不应选择上面的方案。
总结
网络问题的定位,通常都不是非常容易,但是如果通过wireshark等抓包工具来配合研究协议和报文,一般会事半功倍。TCP和HTTP是值得投入时间来学习和研究的协议,因为它们就是迷雾中的灯塔,虽然你不知道岸在何处,但是你却知道没有偏离航向,到达彼岸只是时间问题。